无服务器计算(Serverless Computing)是一种新兴的云计算执行模型,它让开发者能够专注于代码编写,而无需管理底层服务器。本文将探讨无服务器计算的起源、应用场景及其在数据处理服务中的关键问题,帮助读者全面理解这一技术。
一、无服务器计算的由来
无服务器计算的概念可以追溯到2014年,由AWS推出Lambda服务时正式进入主流视野。其核心理念源于“函数即服务”(FaaS),开发者只需上传代码片段(函数),云平台自动处理资源的分配、扩展和维护。这消除了传统服务器管理的复杂性,响应了云计算向更高抽象层发展的趋势。无服务器的“无服务器”并非字面意思,而是指开发者无需关心服务器运维,由云提供商动态处理基础设施。这种模式推动了微服务架构和事件驱动应用的普及,成为现代应用开发的重要范式。
二、无服务器计算的应用场景
无服务器计算适用于多种场景,尤其在事件驱动和短时任务中表现出色。常见场景包括:
- Web和移动后端:处理API请求,例如用户注册、数据查询,自动扩展以应对流量波动。
- 实时文件处理:如图像或视频上传后触发函数进行压缩、转换或分析。
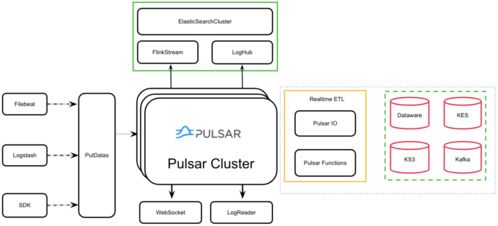
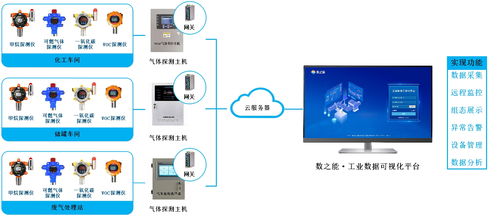
- IoT数据处理:从物联网设备接收数据流,执行实时过滤和聚合。
- 定时任务:运行定期作业,如数据备份或报告生成,无需手动配置调度器。
- 聊天机器人和AI服务:处理自然语言请求,集成第三方API实现智能响应。
这些场景得益于无服务器的弹性伸缩和按需付费特性,降低了运维成本和开发门槛。
三、无服务器计算中的数据处理服务问题
尽管无服务器计算优势显著,但在数据处理服务中仍面临挑战:
- 冷启动延迟:函数首次调用或闲置后重启时,资源初始化可能导致响应延迟,影响实时数据处理性能。
- 状态管理问题:无服务器函数通常是无状态的,难以维护长会话或复杂数据流,需要额外服务(如数据库或消息队列)来持久化状态。
- 资源限制:云提供商对函数执行时间、内存和并发数设限,可能阻碍大规模或长时间运行的数据处理任务。
- 调试和监控复杂性:分布式函数环境使得问题追踪和性能分析更困难,需依赖专门的工具和日志服务。
- 成本控制:虽然按使用付费,但高频或大数据量场景下,费用可能意外飙升,需精细优化代码和资源配置。
无服务器计算通过简化运维、提升弹性,正在重塑数据处理服务的方式。开发者应结合具体场景权衡其利弊,例如在实时性要求高的场景中优化冷启动,或集成其他云服务以弥补状态管理短板。随着技术演进,无服务器有望在边缘计算和AI领域发挥更大作用,推动数字化转型的深入。